Here I present the 4th blog in the DevOps series showcasing our learning while #scalingup. Read our previous blog to know about the lessons we learnt from our scrum.
Most DevOps patterns are exhaustive and would need some strong commitments, in terms of both time and effort which is why many a times people hesitate to introduce DevOps to their teams. Because there usually is a lot of change required in your way of working and the way your workflow flows when you try to retrofit a DevOps into your setup. More so if you did so without thinking hard about the consequences. So how did we create a continuous system of delivery? How did we make a system that is robust yet flexible enough to incorporate the needed changes?
DevOps has a unique challenge. It is difficult to retrofit DevOps into a running system and doing that is not going to directly bring revenue. So in a running startup setup we simply cannot imagine stopping everything, spend time exclusively on this and then go back to our other tasks. But it does not mean that we can’t’ have a functional DevOps, it only means we have to go from MVP (minimum viable product) to MVP on this, and the earlier MVPs might seem pretty embarrassing but it is useful to prove the concept first and then go on and build the concept. Else you might end up with a sophisticated solution that is working but may or may not be what you need.
I have already talked about our thought process where we are against blindly reinventing the wheel or retrofitting someone else’s wheel onto our vehicle. The same goes for DevOps, barring obvious things, we never did any upfront development for DevOps or DevOps processes, rather we went step by step automating bits that we could and bureaucratized bits that we couldn’t. And then went back and discarded the failed MVP, and formalized the ones that have passed. And as always kept doing it. Because above all DevOps is a result of the Agile attitude more than anything else. If you are not thinking agile when you build your DevOps, then you will end up with a random bunch of automated tools, and not a living, breathing system of delivery.
So, here are our bunch of tactics that we used at different times during our evolution to achieve a successful clockwork.
Forms
The most bureaucratic of them all. Forms are the ultimate icon of a bureaucracy. Whenever you want any service done from any bureaucracy, you have to fill a form. And it definitely looks uncool. However there is a reason why it is still going strong across the world both offline and online. The primary benefit of a form is that you get all the data you need in the correct format and it is easy to find out if any required data is missing. This helps because data being missing can be addressed at the very beginning and not later on. Where we use forms is when one group of people need a service done by another group whose work is totally different from the first. For example, when developers want the deployment team to deploy something somewhere (any of our test envs or staging or production) now a developer could do it. But the deployment team owns the passwords and access to the staging and production setups which devs do not have and they also own the best practices which the dev team may not know. One of the problems they faced was that each developer had a different idea of how to push their artifacts to production. For devs of one domain, just copying code was enough, others needed binaries to be changed, still others wanted binaries and configurations to be changed. Some needed process restarts and others did not. Some needed server restarts while others did not. For some devs running an update script was enough while for others some other thing also had to be done. It was very difficult to keep track of these. One solution would be to have the deployment automated. And that is where we eventually reached. But that was not a one day job, and till that was done, we could not have stopped deployments.
So we needed to make sure that the deployment team had the right info when the request was made and not then the team had done half the deployment. We experimented with emails, but most devs wrote what they thought was relevant and not what really was relevant. So we asked developers to mention all that was needed. But that also was not too clear a requirement. And many still missed the requirements. So we created a form. The biggest advantage, is that the developer cannot now accidentally miss any important info. It is difficult to miss info when the form explicitly asks for info. So now developers fill all the info even the ones they think are obvious or irrelevant. And the deployment team was now empowered to act like a bureaucracy and reject a form for data not filled. This worked like magic, our deployments became less buggy and there was far less cases where dev and deployment teams were arguing about what they meant when they said something. The direct result of adding deployment forms was that our deployments were now far less broken.
Checklists
It is the checklists that eventually gave us the idea that forms can also work. Checklists are the zero brainer tool of choice for a lot of people. And it has been so for almost a century now. Perhaps more. However the power of checklists are often underestimated or ignored. You need to read The Checklist Manifesto – by Atul Gawande, to understand how important and valuable checklists are and how crazy it is to ignore them. There was a huge list of things that we were many times not doing right or missing small or obvious steps. And no matter how much we tried we would many times repeat the same mistakes over and over again. And usually our bandwidth was too tight to go deep into each of those issues and find out what went wrong. The responsible person would say that they have done each step as it is supposed to be done. Obviously they did not think that they had done wrong. Because if they thought they were doing the steps, wrong they would not have done it the first time around. No one likes to do the same things repeatedly. Of course many such processes eventually got automated, but till they did, there needed to be a solution. Also not everything can be automated. So we created checklists for every repeated process. And placed them in prominent and easy to find places (physically and in our intranet) This also worked like magic. Soon the number of errors in repeated processes saw a huge fall. Once the errors reduced, the people handling those tasks got more time and bandwidth and they had time to fix their processes and also to automate them. This way the manual process need to be no longer done by a human. This brings us to the next step.
Micro Automations
While it was clear to us long time back that there needs to be a lot of automations in our day to day work, there was one thing that did not allow us that immediately. And that was that automations take time and usually features for customers had highest priority and lowest available times. So when do we spend time on automations? For some time we just postponed the automation work thinking that after the present set of issues are finished, we would have time to work on automations. However we soon realized that this is a mirage and being the startup that were, getting bandwidth for this sort of thing will not be a reality any time soon. But does that mean we abandon it and the benefits that they would bring ? No, what we did was, we took time to make sure that whatever bits we could automate, we would. And make sure that we keep using it unless it was totally unusable.
We made sure we set out to automate only small bits. I call the process Micro Automations. As the name suggests, we only automate a small bit at a time. We also ensured that each bit that we automate is SMART, (specific, measurable, achievable, realistic and time bound). And also we made each bit small enough that it can be done part time by one or two people knowing very well that the main features clearly have priority.
This ensured that over time, we automate more and more bits of processes like our build systems, deployment process, automation tests etc. Bit by Bit. Over time, however we achieved a lot. Finally after all these months, we look back and marvel how much we have actually achieved. As the old adage went, we won the race, by being slow and steady.
There are many more such things that I would like to talk about, but I would like to limit myself to the bureaucratic ones that we attempted. We wanted to make sure that our focus was on the problems pCloudy was supposed to be solving for our customers, while at the same time, we ensured that we were also becoming future ready and being more and more ready to scale further as an organization. Your comments and insights are welcome. I would like to have a conversation about that in the comments section.
This is the third blog in the #scalingup series. Read the previous blog to find out more about our DevOps journey while scaling up.
What is Scrum ?
No Really, What is scrum ? How do you define Scrum ?
A Scrum, as you can see in the image below, and as per wikipedia, is the method of restarting play in a Rugby game that involves players packing closely together with their heads down and attempting to gain possession of the ball.
I am pretty sure that is not the definition that you wanted to see, at least not in this blog. But, bear with me for a couple of seconds. It was not a failed attempt at a bad joke. I just wanted you to see the imagery and get a feel of what is happening. Also I wanted to throw some light on the history of that name. How did a Rugby method give its name to the popular Agile methodology that we use almost throughout the software engineering world.
An oversimplified definition of scrum is that it happens to be a common Agile framework where actions are planned to be completed in timeboxed intervals known as Sprints and progress is tracked on a daily basis in short meetings known as Daily Scrums. This daily Scrum is a stand up meeting with team members standing in a rough circle and explaining their set of points. Since this arrangement looks like a civil version of the Rugby Scrum, both the daily meeting and the process take the name of this particular Rugby activity. The point of this is that the entire team meets, gets to know the statuses of all the activities being done, finds mechanisms by which anyone who is stuck gets help and any one should also be able to suggest improvements etc. Because of this nature, It also allows for course corrections and other changes needed to make sure that what was planned for in that Sprint is indeed completed within the same sprint. Everyone is present to tackle whatever situation is there at hand. Both in Rugby and in this Agile Methodology. Hence the name is shared in both the disciplines.
Scrum is probably the most popular of all the Agile Methodologies in the software engineering world now. It is popular because it gives you as a team manager and as a team member a lot of freedom and expects you to fill only the minimum amount of documentation. It also offers both stakeholders and developers opportunities to reconsider and change their minds about requirements, architecture and other stuff that is usually set in stone in an upfront manner in other older methodologies. If you need to change any of these, you only have to wait till the end of the sprint. It also has periodic feedback built into it which is facilitated by Sprint Review & Retrospectives & the availability of a dedicated Product owner gives you the ability do a lot of experimentation with your feature set before arriving at a final one.
And it is for these reasons that we chose scrum as our Agile Methodology of choice. And it made a lot of sense. After all, we had seen a lot of benefits of scrum in our previous organizations and have been able to make good use of the same here too. But the sailing was not smooth. At least not in the beginning. Here were the primary reasons.
Non Constant Tasks during a Sprint: pCloudy is essentially a SaaS offering and that too in a startup frame of working. So this usually meant that some issues that crop up, mid sprint which might be important for some (important) customer, and the priority therefore gets bumped up. This would mean that developers have to strategically pivot and fix those issues leading many times obviously to the issues that were originally planned getting sidelined. So the usual 2 week sprint got broken all too frequently and this meant we had unfinished tasks at the end of each sprint, which was definitely not desirable.
Sprint Length: The ideal sprint length is considered to be 2-3 weeks with the most popular length being 2 weeks. This is ideal because it is short enough for a feature to be completely done from end to end and yet be short enough for stakeholders to experiment with features and decide to pivot if needed. However with many customer related interruptions coming, we decided to reduce the length of a sprint to one week. The idea was that we would take in this kind of customer interruptions only in the next sprint, which never would be more than a week away, and with this whatever we planned for in the sprint would be completed. However what we say here was that a week was usually not enough time for a feature to be completely developed, let alone it being tested and deployed. This meant that at the end of the sprint, most of the features were not “done-done”. They would be in various stages of completion. Another issue we faced was the length of the review and retro meeting of one sprint and that of the planning meeting for the next one.
So here is what we finally arrived at, which takes the best principles of Scrum but at the same time be able to be as Agile as possible. Remember, we are not here to be Agile Champions, So Agility is very highly desirable, but not indispensable. We did some modifications to our process, once small change at a time and kept doing those changes, here is what we look like now. But As our changes continue, I am pretty sure our methodology will not look like what it looks now even 6 months down the line. Here are the most salient items from our thought process.
Sacrosanct Backlog:
Backlog Storage: Every Feature that we need to pick up is stored in a backlog. We used JIRA for some time and have now migrated to Trello. But the point is that our Agile Backlog is stored in a automated tool. Tomorrow, if our team’s complexity changes, we may chose something else, but the point to note is that team members are able to access the backlog and are able to see all the items they are required to work on and report all changes in statuses. With both JIRA we had used the Kanban like board that the system provides and Trello by default comes with this board. This board was one of the most important artifacts used by the team.
Also we changed our methodology in such a way that while the Backlog itself is sacrosanct, but we allowed ourselves to change the backlog of a sprint to ensure that our customers are not waiting. But unless something earth shattering happens, we do not interrupt a particular task before it is finished. So strictly speaking, we are not doing Scrum, we are in fact doing something more in line with Kanban with some trappings of Scrum like Planning, Review, Retro and of course the Daily Scrum. While we continue to internally call the daily meeting a Scrum out of habit, we also do not pretend that our process is Scrum. It is now a form of what many people call the “Scrumban” where the best features of Scrum and Kanban are merged together to form a practice that looks like both. We have found that at this time, this suites our business and development needs best.
One Scrum / Many Scrums: We were once a smaller team and hence it made a lot of sense for the entire team to have a common scrum, but as the team became bigger, the scrums dragged longer and both heads and legs began to ache. We then divided the team based on the specific area that each of the team worked (Portal, Devices etc) and had each team have their own Scrum. Then all the Scrum Masters of each team had another “scrum of scrums” where the larger team could focus on larger goals. This made each scrum shorter and each scrum more relevant for each attendee.
Management View: Previously since the team was small, the management found it easy to sync with each team member and follow their pace of tasks with a single tool like JIRA or Trello. However as the team grew, the management needed something more robust and flexible to track their day to day tasks. We started with a shared Google sheet that managed the status of each work item which was always updated and visible to management. The shared Google sheet while easy seemed a bit flimsy. We then moved to something a bit more formal with Atlassian Confluence. Now broader level tasks are looked at in Confluence, which break down to smaller issues in Trello for each developer to work on. The scrum masters make sure that Confluence is updated based on the status of the tasks in Trello. Also the confluence report has links to the trello issues.
So what is next and what is the way forward ? Well I do not want to answer that question. That question takes the fun out of the journey, the fun of not knowing what you will discover at the next bend, what you will invent at the next bend. However as I have kept saying, ours will be a journey where we continue to tweak our processes so that it fits us at every phase of our growth. We are still young as a company and still growing and we need to be able to continue tweaking, at least till we are in a few hundreds in terms of headcount. But that doesn’t mean we are blind about the future, and we have no idea what to expect. In fact on the contrary, every tweak we make also comes with the question, how long will this stay and what do we need to do when we outgrow this phase. This is a constant question that we put to ourselves and make sure we have answers. Whenever we don’t, we step back and replan.
Appendix
Before I sign off, let me also throw some light on the experiences we had with some of the tools that we used to track the development. Also a small tidbit about compliance.
Plain Excel / Google Sheets: A Spreadsheet software is the simplest and most flexible mechanism to track virtually anything. In fact it is this simplicity that tempts a lot of people to Run their Software Agility through a series of shared Excel sheets. We too had the same experience, but the only problem is that if you have to manage complex calculations and deductions, then the number tasks that you have to perform to keep your sheet in control becomes difficult to manage. This is not a problem if this is the main thing you do or if you have people to do it for you, otherwise it soon becomes very cumbersome.
JIRA: Jira is a globally popular Issue Management System which is very very helpful in tracking issues. It also deals well with dependencies and broken down tasks. It does what it does very well. But it has one issue that makes it a bit difficult for a fast paced startup. And that is it is very rigid and inflexible. And maybe it was designed that way and it was intentionally not made too flexible, so that there are not too many changes done. I wanted some changes in the workflow that was specific to the work that we were doing and I could not quickly do it. Remember altering JIRA was not the only or the most important work that we were doing. I tried a lot to understand the complexity of JIRA under the hood, but I could not achieve something as simple as adding as many more columns to the JIRA kanban board as I wanted. I know it could be done as I have seen something like what I wanted working elsewhere, but I simply did not have the patience to understand the arcane JIRA workflow editor and other such entities in it. I understand, this is probably a job for a JIRA admin, but we were not so big to recruit one to do the customization for us. So for now we went to another tool from the Atlassian stable. Probably we will revisit JIRA when we grow bigger. And that brings us to the tool we are using now.
Trello: We have right now all but settled on Trello. Trello is another project tracker from Atlassian. It is built around the Kanban board and hence allows you to do a lot of changes to the Kanban Board, including custom columns(we view them as states). We liked it a lot, since I can now track the exact (and many times specific to pCloudy) state each item is in like Backlog, Requirements, Design, Test Planning, Coding, Testing, Code Review, Ready to Deploy, Post deployment Sanity and others.
Compliance: One common thing with these tools is the amount of developer (and tester and devops engineer) compliance. The success of any of these tools depend on the readiness of the developer to actually update statuses in these or any tools. I have see this for the past 15 years that many developers, including me when I was a fresher, simply do not want to do this. Somehow they are ready to spend nights and weekends in office running behind an elusive bug, but spending 5 minutes updating the tool is many times anathema. You have to make your developers see that it is imperative to do the necessary status and other updates in these tools. If your developers do not do it, then none of these tools will be useful. In the end these tools as much for the developer as much as it is for a manager, but they will work only if they are used properly.
Share with me the lessons you have learnt from your daily scrum in the comments section. Keep a watch on this space for my next blog in the #scalingup series.
This blog and a few upcoming ones in this series will talk about our Devops journey and the lessons we learnt while scaling up in a short span of time.
[xyz-ihs snippet=”quickLinks-scaling-up”]
pCloudy’s DevOps Journey
We at pCloudy have been serving your mobile testing needs for 3 years now. And these years have been a wonderful roller-coaster of experiences, ranging from successes, achievements, near misses, not so near misses, crazy deadlines, demanding customers and above all lots and lots of learning.
We have had numerous challenges at various stages of our journey. Each phase of our journey came with specific sets of challenges and each time we surmounted those challenges, there were many insights, lessons and some time even ah-ha moments. But each of these learning howsoever small have in a way contributed to what we are right now. It has made sure that he product is stronger than ever before and growing faster than ever before.
And this learning is what we feel is very important. After all it has molded us in many ways. And we feel that this set of experiences will benefit others who may want to down the path that we took. This blog is an attempt to do exactly that, specifically with the DevOps part of our journey. I, Prashanth Nair, heading the tech department at pCloudy, will try to give you our perspective on the challenges we faced while building a robust DevOps. And overall this blog is an attempt to give you a ring side view of our thought process behind our DevOps decisions.
This post and a few subsequent ones in this series will talk about specific aspects of DevOps and our experiences with them. Here are a few of the items that we plan to talk about. I will be updating this page with links for those items as and when they are ready. There might be others coming up, keep watching this space for more info. If you have and experience.
For any software development team, a source control is paramount. This post chronicles our scaling journey from a small team that used a simple strategy to the present system where close to 30 developers can work together simultaneously and do not step on each other’s metaphorical toes. It also details the branching policy we setup and how we created our testing and DevOps around the new branching model. Read More
Sir Winston Churchill once said “Plans are nothing, planning is everything”. In the context of a Sprint, what it means is that your team should have a plan to refer to, even if the original plan, the one agreed upon during the Sprint planning no longer is valid. You should constantly keep planning so that, you can react to changes in your present set of conditions that you are working with. How do you reconcile scrum with unplanned eventualities? How do you make sure your goals are still met? How do you ensure that your team is focused on completing the goals even when there are changes in your plan. And how to make sure your plan stays unchanged. This post gives you a look into why and how we pivot, how and why we decide not to. How do we course correct on a daily basis ? And finally how we have our daily Scrum and how it has changed over the years. Read More
Most DevOps patterns are exhaustive and would need some strong commitments, in terms of both time and effort. This usually is also the reason that people hesitate to introduce DevOps to their teams. Because there usually is a lot of change required in your way of working and the way your workflow flows when you try to retrofit a DevOps into your setup. More so if you did so without thinking hard about the consequences. So how did we create a continuous system of delivery? How did we make a system that is robust yet flexible enough to incorporate the needed changes ? Read More
Dealing with howlers and perfectionism. Code review for Dummies
Everybody does code review. But does it actually work ? How did we ensure that our code and our blood pressure stay in top shape, while at the same time maintain a feature turnaround time that allows neither. What were the lessons we learnt ? How much code review is too lenient ? how much is too strict? How do we deal with tech debt ? This blog post will delve into the our style and nuances of code review and also look at the specific problems we faced and how we resolved them. Read More
General purpose tools and how they helped us
This is more of a philosophical rant about the inherent urge that many software engineers have about reinventing the wheel, and how that prevents us from using really good tools that are available in the market causing productivity to suffer. I will give examples of how with the right tools we have managed to speed things up or made things less error prone or less boring or more automated. With each example I will show you how we became more productive with each class of tools and made work that much less difficult. Stay tuned for this upcoming blog in this series.
Let us know about your DevOps journey and how did it help you scale up in the comments section.
This blog is a continuation of our #Scalingup blog series. Read the first blog of the series to know about our learning from our DevOps journey.
A source control is the backbone of any DevOps setup. In fact a source control is also the backbone of any software development endeavor. It’s not a question of why SCM, it’s a question of which one?
The next question is how best to use it. As a company that started from a very low developer count few years back, we had a certain set of processes which were ideal for the situation at that time. Now with around 30 odd developers we found ourselves soon outgrowing the same ideal processes. This was reflected in many instances of botched deployment (luckily only on Staging), overwritten code and merge conflicts. We then began tweaking our processes and in due course we have become many times more efficient.
This post chronicles that scaling journey from a small team that used a simple strategy to the present system where all these people are working together without stepping on each others metaphorical toes. It also details the branching policy we setup and delves into how we created our testing and Devops processes around the new branching model.
An oversimplified overview
Before I jump into explanations on our older and present processes and git strategy, I would like to show you a customer’s view of pCloudy just for reference.
pCloudy Access devices remotely from anywhere
At a very high level, pCloudy is a cloud based SAAS that hosts physical mobile phones and tablets which you can access through your browser and can use for your mobile apps testing needs.
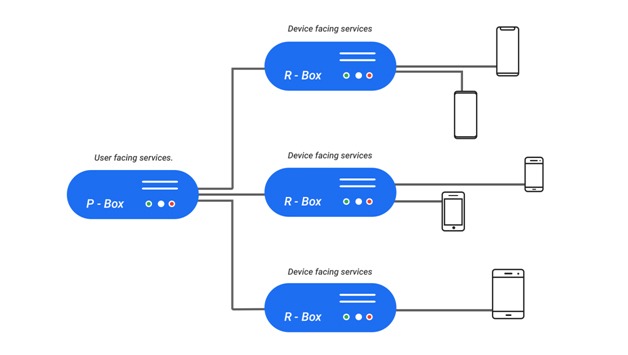
A very basic view of our cloud architecture is as follows.
We have a bunch of services running on the cloud which together we call as the pBox (pCloudy’s Box of services). We also have some physical machines to which the phones and tablets on our cloud are connected. We call them the rBoxes (remote box, this one is an actual physical box). Mind you this is a heavily oversimplified view. I have glossed over some of the complexity and over simplified some details here, else I will end up spending the next several blogs explaining only this. But this simpler representation will help you understand our overall cloud better.
We have a Dev cloud and a Staging cloud in the architecture mentioned above. These are for our internal development and testing respectively. Both these clouds are replicas of the production public cloud. The difference is mostly only in scale.
Teething problems
Now that you have a basic idea of our processes and our architecture, let us dig deeper. I will start by explaining the process that we followed when we were a smaller company and had very few developers. At that time almost all developers worked on different software components independently. Each component had a repo in git. Thus there usually was only one person handling code per repo. This was a very good scenario since every developer knew all the changes happening in their repo inside out and in most cases you could be sure, your changes would work on production once you have tested on your machine, not that I advocate direct deployments to production. That was a simpler time, and our setups were simpler. At that time, the only strategy regarding source control was that we needed to use one. Primarily because no need was felt for more sophistication. (and the resulting complexity).
But as our headcount increased we ran into issues. Being able to constantly keep increasing headcount is an indicator of success, but that comes with its own set of problems. The primary one being managing the code’s journey from the developer’s computer to the cloud. Our major architectural blocks and software components more or less remained the same, but most components now have multiple people working on it, one of them usually being a new employee. This person is not only new to the team, but also has no idea of the nuances of the process that we used to follow before they joined. More people also meant more points of failure.
So what did we do? We did small tweaks. And kept doing those tweaks. And never stopped.
Evolution over Revolution
So why small tweaks ? Why not bigger changes ? Well, as a matter of philosophy, our approach is to avoid disruptive big bang changes in a running system unless it is unavoidable.
What we realized early on is that a copy-paste job of what worked elsewhere may not work here. Every company is different. And so are the constraints that each team works under. I am not claiming that our problems are more difficult, just that they are different. For similar reasons, we do not directly start implementing a process just because it showed results elsewhere. I will give examples of this as we go ahead in this series. But for now, it was clear that while we are not going to reinvent the wheel, we are also not going to be very successful taking someone else’s wheel and fitting it on our vehicle without much thought.
Like a lot of startups, when we started up, our goal was to make the most awesome product that we could make and not be an Agile/Devops champion. Starting out with any other goal in my opinion is neither smart nor would it have taken us far. Because the product is the reason for us to exist. Also while there is a lot of data and material on Agile and good Devops, what really matters is how you take each principle and implement it for your team in such a way that your team’s and business productivity is more than it was before it was implemented. If this condition is not met, then either you have not done your implementation right, or your team is not yet ready for that.
So we did small tweaks ? Many of them over time. Till the needs are met. And we will keep doing them if our needs change.
Our Tweaks
Most of our tweaks were in the following few areas.
Git branching model.
Approval of code review.
Mapping branches to environments.
Let me now explain in a bit of detail
As I said before earlier we did not have any standard branching model. And since there were fewer people working, deployment was not much of a hassle. But as our team strength increased, problems started cropping up. Especially when more than one developer worked on the same files in the same repo.
The main problem we saw was developers were inadvertently overwriting code written by other developers. This usually was because someone pushed their code into the repo without first checking if someone else had also done the same. This is a human problem. It is very easy to make this mistake. Humans forget stuff. Briefly we experimented with a checklist to be followed by developers before pushing code into the source control. But the results were not conclusive.
So we pivoted. We forced a standardization of our git branching model. This change was bigger than a simple tweak. It was a relatively big change but we went ahead because it was not avoidable. And previous lack of a standard process had the potential to hurt us in the future. Now two years later, this looks like a no brainer. But we did spend a lot of time deliberating over this before finally choosing git-flow. We derived our branching model from that. You can find detailed explanations of the model here, here and here. But let me summarize below what git flow is and why we chose it.
Git Flow
This diagram here is a good summary of what git-flow looks like.
Essentially what Git flow provides is what I call a “Staged Promotion” of code. You have various git branches (usually Master, Develop and multiple Feature branches). Depending on what stage of development your particular feature is in, your code will reside in a different branch. Your feature (or bug fix, or enhancement) starts its life in a feature branch, a branch created specifically for that feature. A developer does their development there and once they are satisfied of the feature’s completion, the code is pushed to the Develop through a pull request. The pull request then gets reviewed and merged. This fulfils an important goal. When you push code to the any Branch, you do that through a pull request and that forces a code review. Your work cannot progress without it. This in my opinion is the biggest advantage of a “Pull-request” based process. You can do as many changes here as needed, the only thing to note is that your code gets deployed from git and not through random copying or modification of individual files. This is the branch where code from all other developers get integrated and verification happens. Once verified, the code is deployed and pushed to master.
This allows for a stage by stage verification of code with the code getting promoted after every stage is complete. Also because of the fact that promoting the code needs pull requests, code review is built in to the process.
Git Flow with our approach
Our process is derived from git-flow but is not exactly the same. We have more branches, (Features, Dev, Staging, Master) more or less to make sure that our Dev and Staging clouds are used properly. In our case, development starts on a feature branch and when the developer is satisfied with his work on his machine, he sends a pull request to the the Develop Branch. Once the pull request is approved, the code gets deployed on the Dev Cloud from the Dev branch.
Once you have seen that your code is working properly, you push it to the test branch in the same manner to enable formal verification of the setup. The code on the test branch gets deployed on the Staging environment. Here your code gets extensively tested before it is declared pass or fail.
If it passes, then you have permission to send a pull request to the master. The code in master corresponds to what we have in production. If it fails, then it goes back to the dev branch or his feature branch for the developer. The developer fixes the code and then starts the same process again. This ensures that we break the code as less as possible and if we ever do, it is usually because the process hasn’t been followed.
Now the next question is what happens to the code that is deployed to the test branch and the Staging cloud after tests fail. We periodically reset the internal clouds from master. This unpromoted code gets automatically discarded during such a reset. This is crucial, else you will have code in your Develop or Staging environments that you never intend to push to production.
So this was overall our Git Branching strategy. But before I finish this blog, I would like to leave with a set of other insights that we gained while perfecting this part of our devops.
Insights
Never get a human to look for mismatched brackets: I have lost count of the number of times we have had failures in Staging and sometimes Production too because of simple errors like mismatched brackets or missing commas in a json structure or something that looks equally trivial. And this has led us to wonder how something like this was missed in so many code reviews. And then the coin dropped, we realized that errors like this are indeed difficult for the human eye to see. So we settled for the next best thing. Static Analyzers for the code. And after we used one, we began to wonder how did we ever live without one till now. There are literally hundreds of them in the market. We chose CodeFactor, partly because it integrates with github and you see all the defects directly in your pull requests and partly because it works with many languages.
Small is beautiful: At least with check-ins and pull requests, we have discovered that smaller but numerous check-ins and pull requests are the way to go. It is far easier to review smaller deltas. It is also far easier to revert if there are problems. Also smaller changes are easier to test and certify.
Code Review works best in person: Granted, github (and others) gives you a very sophisticated UI where you can see the code delta in a diff-view and also allows you do have a conversation about the code and the changes. But I have seen that the best review happens in person. Face time is the best, if you have a query about a a review comment on your pull request, it is always better to just walk up to the person in question and clarify rather than lazily type a one line response. At best you will receive another response which may or may not finish the clarification, and at worst you will end up with a long chain of back and forth after which you give us and have a face to face conv. Sometimes your reviewer may even ignore because they have more pressing things to do, in all these cases it is your loss.
So that’s all I have for today. Feel free to respond through comments. I would love to continue the conversation. Keep watching this space, there will be more blogs from me about the insights and learnings we gained doing DevOps in a startup.