
Most testing practices aren’t broken. They’re incomplete.
The distinction matters because the solution is different.
A broken practice needs fixing — find what’s wrong and repair it. An incomplete practice needs connecting — take what exists and make the layers work together. Most teams that struggle with testing quality, release confidence, or engineering-QA tension are dealing with the second problem while looking for the first.
They have tools. They don’t have a practice.
The difference is whether the output of each layer becomes the input of the next — whether the whole compounds, or whether the parts just coexist.
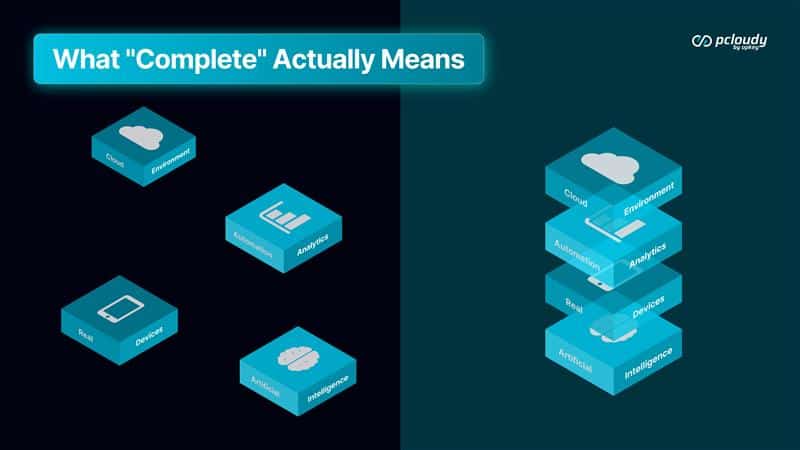
Here’s what complete looks like when the layers actually connect.
Layer One: The Foundation
Everything begins with signal quality.
Real devices provide honest signals. Emulators simulate an ideal device that most users don’t have. 34% of device-specific bugs are invisible on emulators — they only surface on real hardware, with real OS variations, real memory conditions, real thermal behavior.
AI built on top of emulator results learns from incomplete data. Coverage measured against emulator runs has hidden gaps. Release signals generated from emulator test suites reflect a reality that doesn’t exist for users.
The foundation isn’t just about catching more bugs on real devices. It’s about ensuring that every layer built on top has accurate data to work from.
Your environment matters for the same reason. Private Cloud and Lab in a Box aren’t just compliance solutions. They’re signal integrity solutions — ensuring that the data flowing through the stack reflects real conditions in your actual infrastructure, not a shared environment with variable behavior.
The foundation layer determines the accuracy of everything above it.
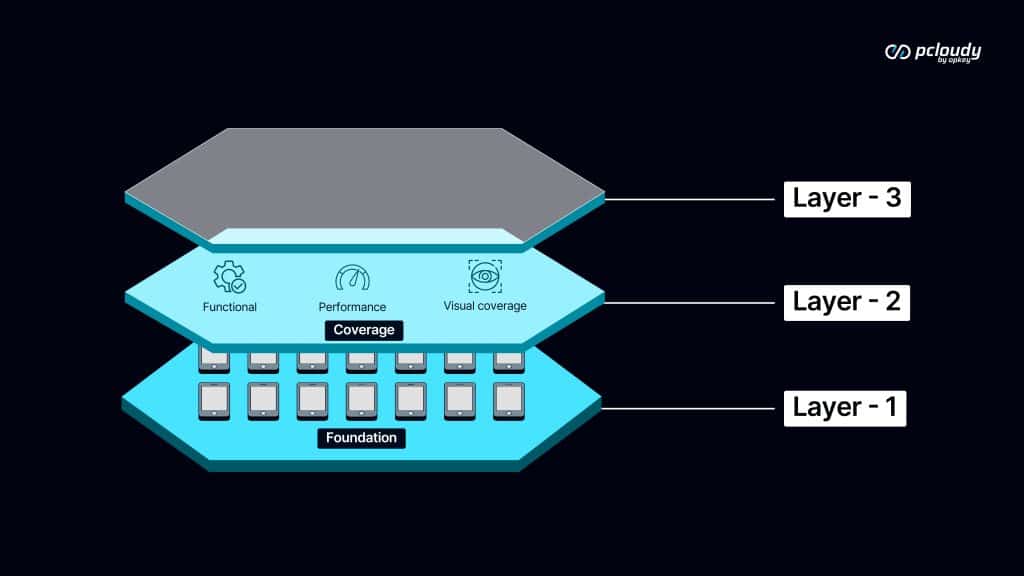
Layer Two: Coverage
Once the foundation is honest, coverage determines completeness.
Functional testing answers whether the app does what it’s designed to do. Performance testing answers whether it does it fast enough for the users who actually hold the device. Visual testing answers whether it looks right across the display variations in your user base.
Each layer catches what the others miss. A functional test won’t surface a layout that breaks at a specific screen size. A visual test won’t catch a checkout that hangs under memory pressure. A performance test won’t catch a login that fails silently on a carrier-modified OS.
The gaps between the three coverage layers are exactly where production bugs hide. And they hide there specifically because most teams treat coverage as a single dimension rather than three simultaneous ones.
Complete coverage isn’t running more tests. It’s ensuring that functional, performance, and visual signals are all present — because users experience all three simultaneously, and a testing practice that ignores one is making a deliberate decision to be blind to that category of failure.
Layer Three: Intelligence
The foundation and coverage layers generate signal. The intelligence layer makes that signal actionable at speed.
Test selection ensures the right tests run for each build — not all tests, not a manually curated subset, but the tests that actually cover what changed. The result is feedback that arrives in minutes rather than hours, while developer context is still fresh.
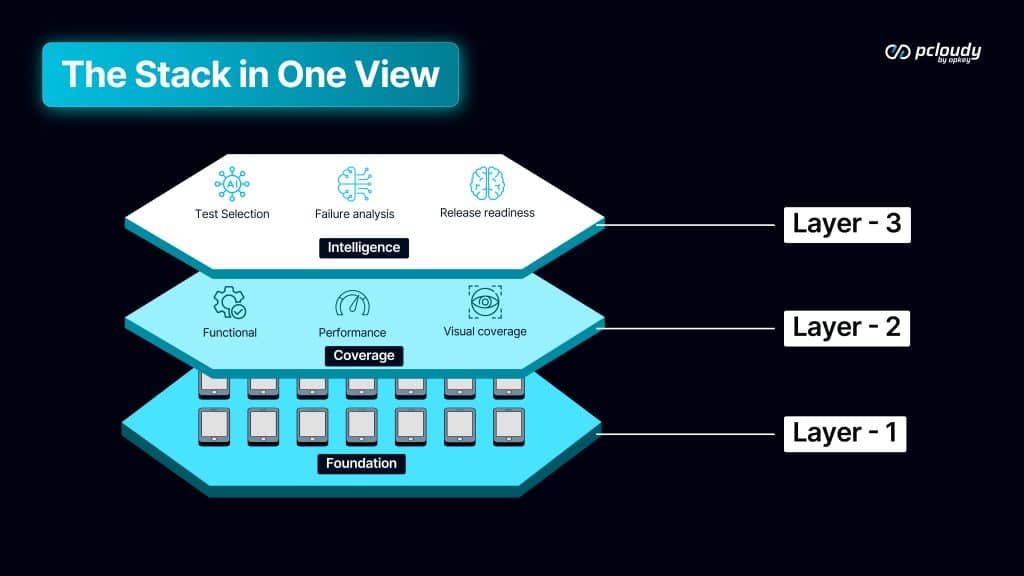
Failure analysis ensures that when tests fail, the triage has already happened before a human opens the report. Real regression, flaky script, environment issue, test gap — classified automatically, with evidence, so engineering time goes to fixing rather than investigating.
Release readiness synthesizes coverage quality, failure severity, risk exposure, and historical patterns into a composite signal that answers the actual question: not “did the tests pass?” but “is this build ready to be released?”
Each intelligence layer is more accurate because of the layers beneath it. Test selection learns from real device results, not emulator approximations. Failure analysis classifies against consistent environment patterns, not variable shared infrastructure. Release readiness synthesizes complete coverage signals, not partial ones.
This is why the sequence matters. Intelligence amplifies what’s beneath it. If what’s beneath it is incomplete, intelligence amplifies the incompleteness.
What the Full Stack Looks Like Running
A developer pushes a change at 10:47am.
The AI analyzes the change, maps it to 847 relevant tests from a suite of 5,400. Those 847 tests run across real devices — the hardware configurations that represent the actual user base. Functional, performance, and visual coverage in parallel.
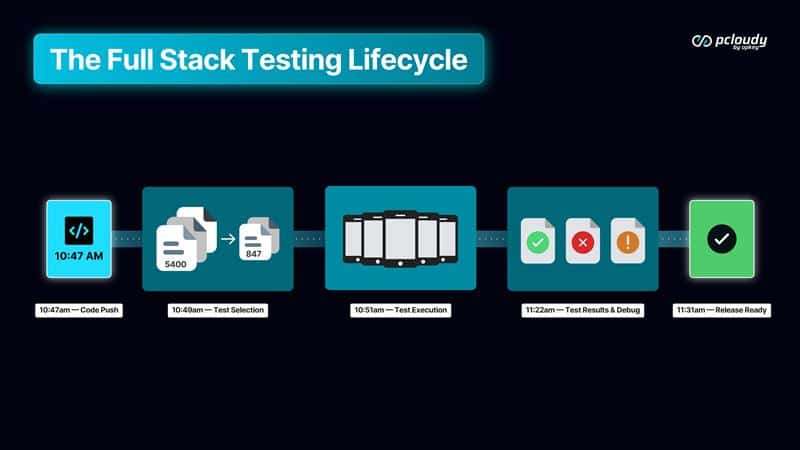
At 11:22am — 35 minutes later — results arrive. The AI tool has already classified six failures: four flaky, one real regression in a non-critical path, one visual bug on a specific screen size. Coverage is 94% of changed code. Risk exposure is low. Historical comparison suggests the build is ready to ship with a minor patch.
The developer has a specific, actionable signal 35 minutes after their push, with full context intact.
No triage meeting. No end-of-day release anxiety. No adversarial conversation between engineering and QA about whether the failures matter.
That’s the full stack running. Not as a demo. As a daily practice.
What Changes for QE Leadership
The outcome that matters most isn’t the metrics, though the metrics are significant. 2-week release cycles to 4 days. 18% failure rates to 4%. Production incidents from weekly rhythm to quarterly exceptions.
The outcome that matters most is the role shift.
When the testing practice produces signal that engineering trusts, QA stops being the team that blocks releases and becomes the team that makes releases possible. The conversation changes from “why is QA holding this up?” to “what does QA say about this build?”
That’s not a cultural change. It’s a signal quality change. Trust follows a trustworthy signal.
And QE leadership shifts accordingly from managing processes to owning quality intelligence. From defending testing time to demonstrating testing value. From reactive to predictive.
The full stack isn’t just a better way to test. It’s a better position from which to lead.
Next week we’re going to explore where testing goes from here. The agentic future, AI that doesn’t just support the testing workflow, but runs it autonomously, with human oversight at the decisions that matter.
