QA & testing become indomitable especially in the context of API testing. The development teams benefit from automated integration tests at API levels as it helps them in easy integration of apps and higher product adoption rate, ultimately helping the firm increase their profits. API layer is frequently ignored while developing and executing automated tests and mostly end to end user interface driven tests are executed to check if final application works perfectly after integration. API layer is not to be ignored and for a QA strategy to be successful, it should consider API testing as a fundamental part of the overall testing strategy.
Let us understand what API testing means:
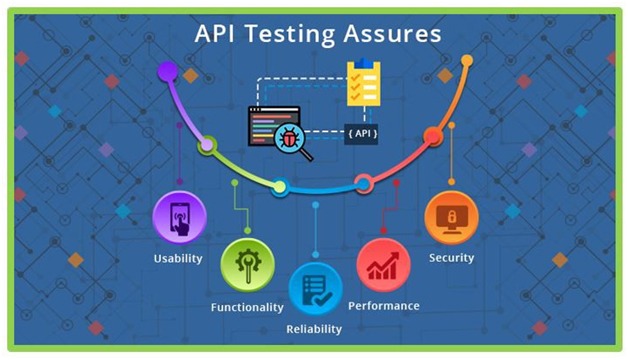
Application Programming Interfaces (APIs) are a set of programs that allow two or more software to communicate with each other and be able to exchange data smoothly. In the testing world, testing APIs is different than other types of testing. UI and functional testing is often given importance while API testing is ignored. The foremost responsibility of a tester is to ensure that API testing is performed in order to attain seamless functioning, performance, and the reliability of different data-driven applications and systems by verifying exchanges and communications between applications, systems, databases, and networks.
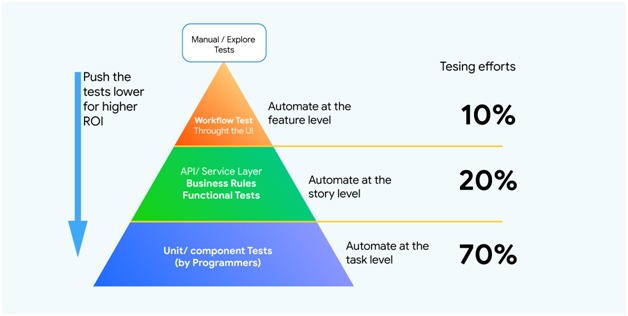
While integration testing has been a component of the test automation pyramid since its inception, it’s also been the most undermined layer in functional test automation. All tests that supercede the scope of an individual unit, and can’t be covered by unit testing are often executed through user interface-driven, end-to-end test scenarios. But while end-to-end tests can be seen as the ultimate integration test, where all components come together, having too many of them leads to test suites that take unnecessarily long to execute, and that are hard to maintain and keep stable. It’s often possible to test important parts of an application’s technical and business logic through an API. To understand the importance of API Testing more in depth, let’s understand the undermentioned benefits of Automated API testing:
Unit tests are often run on small group of components within a single application layer. Issues are often not detected in distributed apps where one application layer ends and the next one begins. In order validate if the components are communicating as desired, API level tests are designed. So, the need of a strong API testing Strategy is of dire importance at the integration level especially when it comes to integrating with external components. Managing the testing environment is a critical task to perform especially when the components are with different teams.
More Stability and Speed as compared to end-to-end tests:
It is true that end-to-end tests are vaster in scope than API testing. They cover all the layers and components of the application but API tests cope up with its loss with its stability and speed. API tests are certainly faster than the former. End-to-end tests take longer time to load browsers and screens whereas API tests are based on individual request-response interactions (for example in JSON or XML format)which makes the execution faster with shorter feedback cycles. Moreover, user interfaces tend to change frequently due to various user change requests and adherence to advanced front end frameworks API tends to be more stable in terms of Interfaces that yields fewer faults and requires less maintenance.
Introducing API Level Testing more seriously- A significant decision in Automation Testing
API level integration testing should be a mandatory aspect of any automated testing agenda. It could be an unnerving move for those with no prior expertise in this area. It is mostly the tester’s cup of tea more than the developer’s as it can go beyond the component or application. The absence of user interface can be a blocker in accessing and testing the API. But you can opt from various automated API testing tools available in the market. Tools like RestAssured, SoapUI, and Postman are preferred among the most.
Conclusion
In the era of Artificial intelligence and IoT, the need for API tests is becoming intense. Automated API Testing strategy is the most effective strategy for faster delivery and reduced human inaccuracies. With the help of the tools, more API test requirements could be covered and API testing could be made more advantageous for secured and quality deployment of mobile applications in shorter time. Why don’t you integrate your automation framework using pCloudy’s API and make your app release faster?
This blog and a few upcoming ones in this series will talk about our Devops journey and the lessons we learnt while scaling up in a short span of time.
[xyz-ihs snippet=”quickLinks-scaling-up”]
pCloudy’s DevOps Journey
We at pCloudy have been serving your mobile testing needs for 3 years now. And these years have been a wonderful roller-coaster of experiences, ranging from successes, achievements, near misses, not so near misses, crazy deadlines, demanding customers and above all lots and lots of learning.
We have had numerous challenges at various stages of our journey. Each phase of our journey came with specific sets of challenges and each time we surmounted those challenges, there were many insights, lessons and some time even ah-ha moments. But each of these learning howsoever small have in a way contributed to what we are right now. It has made sure that he product is stronger than ever before and growing faster than ever before.
And this learning is what we feel is very important. After all it has molded us in many ways. And we feel that this set of experiences will benefit others who may want to down the path that we took. This blog is an attempt to do exactly that, specifically with the DevOps part of our journey. I, Prashanth Nair, heading the tech department at pCloudy, will try to give you our perspective on the challenges we faced while building a robust DevOps. And overall this blog is an attempt to give you a ring side view of our thought process behind our DevOps decisions.
This post and a few subsequent ones in this series will talk about specific aspects of DevOps and our experiences with them. Here are a few of the items that we plan to talk about. I will be updating this page with links for those items as and when they are ready. There might be others coming up, keep watching this space for more info. If you have and experience.
For any software development team, a source control is paramount. This post chronicles our scaling journey from a small team that used a simple strategy to the present system where close to 30 developers can work together simultaneously and do not step on each other’s metaphorical toes. It also details the branching policy we setup and how we created our testing and DevOps around the new branching model. Read More
Sir Winston Churchill once said “Plans are nothing, planning is everything”. In the context of a Sprint, what it means is that your team should have a plan to refer to, even if the original plan, the one agreed upon during the Sprint planning no longer is valid. You should constantly keep planning so that, you can react to changes in your present set of conditions that you are working with. How do you reconcile scrum with unplanned eventualities? How do you make sure your goals are still met? How do you ensure that your team is focused on completing the goals even when there are changes in your plan. And how to make sure your plan stays unchanged. This post gives you a look into why and how we pivot, how and why we decide not to. How do we course correct on a daily basis ? And finally how we have our daily Scrum and how it has changed over the years. Read More
Most DevOps patterns are exhaustive and would need some strong commitments, in terms of both time and effort. This usually is also the reason that people hesitate to introduce DevOps to their teams. Because there usually is a lot of change required in your way of working and the way your workflow flows when you try to retrofit a DevOps into your setup. More so if you did so without thinking hard about the consequences. So how did we create a continuous system of delivery? How did we make a system that is robust yet flexible enough to incorporate the needed changes ? Read More
Dealing with howlers and perfectionism. Code review for Dummies
Everybody does code review. But does it actually work ? How did we ensure that our code and our blood pressure stay in top shape, while at the same time maintain a feature turnaround time that allows neither. What were the lessons we learnt ? How much code review is too lenient ? how much is too strict? How do we deal with tech debt ? This blog post will delve into the our style and nuances of code review and also look at the specific problems we faced and how we resolved them. Read More
General purpose tools and how they helped us
This is more of a philosophical rant about the inherent urge that many software engineers have about reinventing the wheel, and how that prevents us from using really good tools that are available in the market causing productivity to suffer. I will give examples of how with the right tools we have managed to speed things up or made things less error prone or less boring or more automated. With each example I will show you how we became more productive with each class of tools and made work that much less difficult. Stay tuned for this upcoming blog in this series.
Let us know about your DevOps journey and how did it help you scale up in the comments section.
This blog is a continuation of our #Scalingup blog series. Read the first blog of the series to know about our learning from our DevOps journey.
A source control is the backbone of any DevOps setup. In fact a source control is also the backbone of any software development endeavor. It’s not a question of why SCM, it’s a question of which one?
The next question is how best to use it. As a company that started from a very low developer count few years back, we had a certain set of processes which were ideal for the situation at that time. Now with around 30 odd developers we found ourselves soon outgrowing the same ideal processes. This was reflected in many instances of botched deployment (luckily only on Staging), overwritten code and merge conflicts. We then began tweaking our processes and in due course we have become many times more efficient.
This post chronicles that scaling journey from a small team that used a simple strategy to the present system where all these people are working together without stepping on each others metaphorical toes. It also details the branching policy we setup and delves into how we created our testing and Devops processes around the new branching model.
An oversimplified overview
Before I jump into explanations on our older and present processes and git strategy, I would like to show you a customer’s view of pCloudy just for reference.
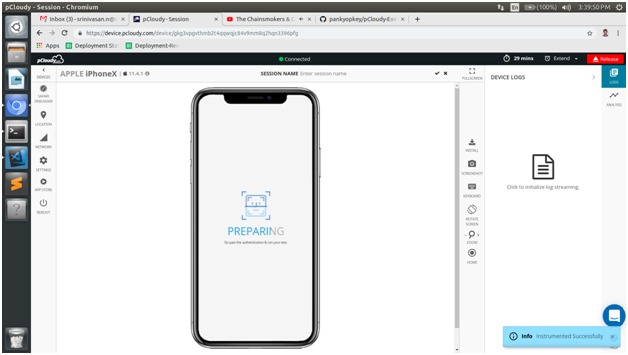
pCloudy Access devices remotely from anywhere
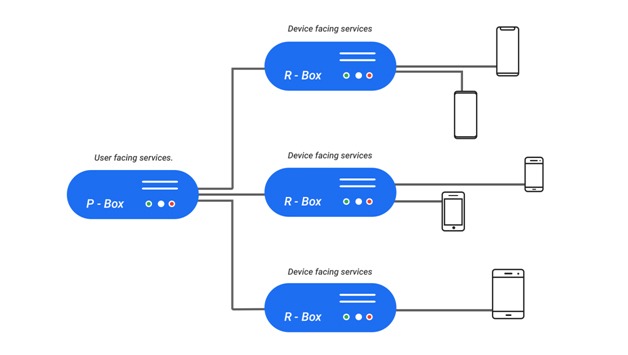
At a very high level, pCloudy is a cloud based SAAS that hosts physical mobile phones and tablets which you can access through your browser and can use for your mobile apps testing needs.
A very basic view of our cloud architecture is as follows.
We have a bunch of services running on the cloud which together we call as the pBox (pCloudy’s Box of services). We also have some physical machines to which the phones and tablets on our cloud are connected. We call them the rBoxes (remote box, this one is an actual physical box). Mind you this is a heavily oversimplified view. I have glossed over some of the complexity and over simplified some details here, else I will end up spending the next several blogs explaining only this. But this simpler representation will help you understand our overall cloud better.
We have a Dev cloud and a Staging cloud in the architecture mentioned above. These are for our internal development and testing respectively. Both these clouds are replicas of the production public cloud. The difference is mostly only in scale.
Teething problems
Now that you have a basic idea of our processes and our architecture, let us dig deeper. I will start by explaining the process that we followed when we were a smaller company and had very few developers. At that time almost all developers worked on different software components independently. Each component had a repo in git. Thus there usually was only one person handling code per repo. This was a very good scenario since every developer knew all the changes happening in their repo inside out and in most cases you could be sure, your changes would work on production once you have tested on your machine, not that I advocate direct deployments to production. That was a simpler time, and our setups were simpler. At that time, the only strategy regarding source control was that we needed to use one. Primarily because no need was felt for more sophistication. (and the resulting complexity).
But as our headcount increased we ran into issues. Being able to constantly keep increasing headcount is an indicator of success, but that comes with its own set of problems. The primary one being managing the code’s journey from the developer’s computer to the cloud. Our major architectural blocks and software components more or less remained the same, but most components now have multiple people working on it, one of them usually being a new employee. This person is not only new to the team, but also has no idea of the nuances of the process that we used to follow before they joined. More people also meant more points of failure.
So what did we do? We did small tweaks. And kept doing those tweaks. And never stopped.
Evolution over Revolution
So why small tweaks ? Why not bigger changes ? Well, as a matter of philosophy, our approach is to avoid disruptive big bang changes in a running system unless it is unavoidable.
What we realized early on is that a copy-paste job of what worked elsewhere may not work here. Every company is different. And so are the constraints that each team works under. I am not claiming that our problems are more difficult, just that they are different. For similar reasons, we do not directly start implementing a process just because it showed results elsewhere. I will give examples of this as we go ahead in this series. But for now, it was clear that while we are not going to reinvent the wheel, we are also not going to be very successful taking someone else’s wheel and fitting it on our vehicle without much thought.
Like a lot of startups, when we started up, our goal was to make the most awesome product that we could make and not be an Agile/Devops champion. Starting out with any other goal in my opinion is neither smart nor would it have taken us far. Because the product is the reason for us to exist. Also while there is a lot of data and material on Agile and good Devops, what really matters is how you take each principle and implement it for your team in such a way that your team’s and business productivity is more than it was before it was implemented. If this condition is not met, then either you have not done your implementation right, or your team is not yet ready for that.
So we did small tweaks ? Many of them over time. Till the needs are met. And we will keep doing them if our needs change.
Our Tweaks
Most of our tweaks were in the following few areas.
Git branching model.
Approval of code review.
Mapping branches to environments.
Let me now explain in a bit of detail
As I said before earlier we did not have any standard branching model. And since there were fewer people working, deployment was not much of a hassle. But as our team strength increased, problems started cropping up. Especially when more than one developer worked on the same files in the same repo.
The main problem we saw was developers were inadvertently overwriting code written by other developers. This usually was because someone pushed their code into the repo without first checking if someone else had also done the same. This is a human problem. It is very easy to make this mistake. Humans forget stuff. Briefly we experimented with a checklist to be followed by developers before pushing code into the source control. But the results were not conclusive.
So we pivoted. We forced a standardization of our git branching model. This change was bigger than a simple tweak. It was a relatively big change but we went ahead because it was not avoidable. And previous lack of a standard process had the potential to hurt us in the future. Now two years later, this looks like a no brainer. But we did spend a lot of time deliberating over this before finally choosing git-flow. We derived our branching model from that. You can find detailed explanations of the model here, here and here. But let me summarize below what git flow is and why we chose it.
Git Flow
This diagram here is a good summary of what git-flow looks like.
Essentially what Git flow provides is what I call a “Staged Promotion” of code. You have various git branches (usually Master, Develop and multiple Feature branches). Depending on what stage of development your particular feature is in, your code will reside in a different branch. Your feature (or bug fix, or enhancement) starts its life in a feature branch, a branch created specifically for that feature. A developer does their development there and once they are satisfied of the feature’s completion, the code is pushed to the Develop through a pull request. The pull request then gets reviewed and merged. This fulfils an important goal. When you push code to the any Branch, you do that through a pull request and that forces a code review. Your work cannot progress without it. This in my opinion is the biggest advantage of a “Pull-request” based process. You can do as many changes here as needed, the only thing to note is that your code gets deployed from git and not through random copying or modification of individual files. This is the branch where code from all other developers get integrated and verification happens. Once verified, the code is deployed and pushed to master.
This allows for a stage by stage verification of code with the code getting promoted after every stage is complete. Also because of the fact that promoting the code needs pull requests, code review is built in to the process.
Git Flow with our approach
Our process is derived from git-flow but is not exactly the same. We have more branches, (Features, Dev, Staging, Master) more or less to make sure that our Dev and Staging clouds are used properly. In our case, development starts on a feature branch and when the developer is satisfied with his work on his machine, he sends a pull request to the the Develop Branch. Once the pull request is approved, the code gets deployed on the Dev Cloud from the Dev branch.
Once you have seen that your code is working properly, you push it to the test branch in the same manner to enable formal verification of the setup. The code on the test branch gets deployed on the Staging environment. Here your code gets extensively tested before it is declared pass or fail.
If it passes, then you have permission to send a pull request to the master. The code in master corresponds to what we have in production. If it fails, then it goes back to the dev branch or his feature branch for the developer. The developer fixes the code and then starts the same process again. This ensures that we break the code as less as possible and if we ever do, it is usually because the process hasn’t been followed.
Now the next question is what happens to the code that is deployed to the test branch and the Staging cloud after tests fail. We periodically reset the internal clouds from master. This unpromoted code gets automatically discarded during such a reset. This is crucial, else you will have code in your Develop or Staging environments that you never intend to push to production.
So this was overall our Git Branching strategy. But before I finish this blog, I would like to leave with a set of other insights that we gained while perfecting this part of our devops.
Insights
Never get a human to look for mismatched brackets: I have lost count of the number of times we have had failures in Staging and sometimes Production too because of simple errors like mismatched brackets or missing commas in a json structure or something that looks equally trivial. And this has led us to wonder how something like this was missed in so many code reviews. And then the coin dropped, we realized that errors like this are indeed difficult for the human eye to see. So we settled for the next best thing. Static Analyzers for the code. And after we used one, we began to wonder how did we ever live without one till now. There are literally hundreds of them in the market. We chose CodeFactor, partly because it integrates with github and you see all the defects directly in your pull requests and partly because it works with many languages.
Small is beautiful: At least with check-ins and pull requests, we have discovered that smaller but numerous check-ins and pull requests are the way to go. It is far easier to review smaller deltas. It is also far easier to revert if there are problems. Also smaller changes are easier to test and certify.
Code Review works best in person: Granted, github (and others) gives you a very sophisticated UI where you can see the code delta in a diff-view and also allows you do have a conversation about the code and the changes. But I have seen that the best review happens in person. Face time is the best, if you have a query about a a review comment on your pull request, it is always better to just walk up to the person in question and clarify rather than lazily type a one line response. At best you will receive another response which may or may not finish the clarification, and at worst you will end up with a long chain of back and forth after which you give us and have a face to face conv. Sometimes your reviewer may even ignore because they have more pressing things to do, in all these cases it is your loss.
So that’s all I have for today. Feel free to respond through comments. I would love to continue the conversation. Keep watching this space, there will be more blogs from me about the insights and learnings we gained doing DevOps in a startup.
pCloudy announces the support for the brand new iPhone XS and XS Max our real device cloud. You can now test your apps on the latest iPhone devices without any wait. Committed to provide you with the latest, we provide you with fast support for latest devices and OS for mobile app test.
Apple iPhone XS
Apple iPhone XSMAX
With users becoming more conscious, it’s very important for companies to make sure that their apps run smoothly on a wide spectrum of devices including the latest released devices and OS. It becomes a mandate for enterprise mobility to test their apps on multiple real devices like the recently launched iPhone XS and XS Max to make sure that their apps don’t fail or have to face the brunt of getting bad reviews or ratings on App store. Get your app quality assured!
To know more about what these phones are offering, you can read this blog. Why don’t you test your app on pCloudy, the unified digital app testing platform, to find out the difference in app quality?
We are very excited! V.5.2 of pCloudy has been released with a number of exciting new features and product improvements. This update brings some path-breaking features, some revamped ones building on previous experiences, more mature than ever before.
Check it out yourself!
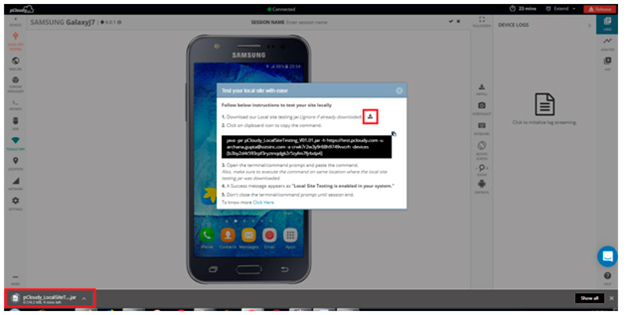
a)Test local or Staged sites with Local site emulation: It’s a path breaking feature for enterprise mobility. For all the users who have been asking for a solution to test their private servers on pCloudy devices before deploying them on production, we have a good news for you.
Now, you can access your site behind a firewall, on a staging server, or locally with pCloudy before it hits production.
Since private servers are internal to your network, they have no public access which makes it difficult to test on a device on cloud. Local Site emulation Testing provides a platform to test private or internal servers on any Android device present on pCloudy. Find the details about this feature here.
b) Test your app with Face ID feature: Apple introduced the ability to perform authentication via FaceID to enable secure and effortless access to the device. But it turns out to be a hindrance for mobility teams while testing their iOS apps on devices over cloud. To ease out the process of authenticating Face ID manually every time, you can now bypass the FaceID verification in your apps using our utility.
With this feature released, you can instrument your iOS app for both TouchID and FaceID on pCloudy. Isn’t it a bonanza for iPhone users? Click here to find out more about this feature.
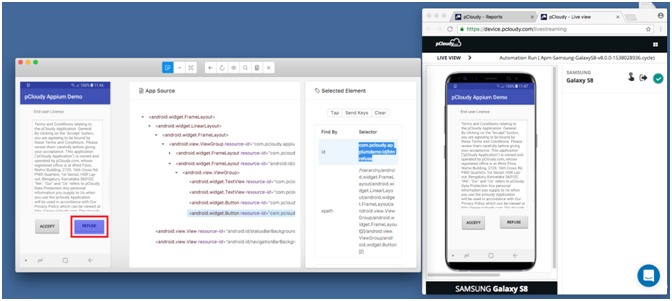
c) Inspecting Element using Appium Desktop: Appium Desktop is a point-and-click interface for using Appium and inspecting your app’s structure. With this new feature you will be able to run Inspector sessions on pCloudy. You just have to login in to your registered account, set up the desired capabilities for your test appropriately, and you’ll be able to drive your app remotely using Appium Desktop. Read More
d) Releasing Follow Me Officially: ‘Follow Me’, the one-of-its-kind feature to speed up the manual app tests has been available on beta version for you to test your apps manually and report us the issues. After a rigorous quality assurance done for the features and fixing most of the issues reported, we are now releasing ‘Follow Me’ officially to manually test your apps in synchronous mode and accelerate it exponentially. Read More
So, the most awaited 2 days long Software testing conference STARWEST 2018 came to an end on 4th October, with the most insightful and pragmatic gathering and discussions to tackle the fast growing ‘software testing’ head-on. When the venue selected is supposed to be the “Happiest place on Earth – Disneyland”, how could you not be rejuvenated to take software testing to a next level.
With the top minds in software testing coming together to share the latest trends, tips on stage and through conference networking opportunities, STARWEST this year too has succeeded in bringing forth excellent insights about future of testing in rapidly changing times. More than 40 top companies participated in this one-of its kind Expo where we have witnessed some of the monumental key developments that would shape testing landscape in the coming years.
Over 1000 software testers gathered and more than 70 empanelled speakers graced the expo for 2 days. Attendees heard from experts like: John Bach from eBay, Adam Auerbach talking about how continuous testing in DevOps will help business achieve business success, Rob Somourin from Amibug.com, Max Saperstone from Coveros to name a few.
In between sessions, the pCloudy booth was flooded with people. Our team of three did their best to answer questions and get feedback from those who are already using pCloudy as well as folks who were new to pCloudy.
Here are the biggest lessons that we learnt at the STARWEST event this year:
Robot Framework is a generic keyword-driven test automation framework for acceptance level testing and acceptance test-driven development (ATDD). It has an easy-to-use tabular syntax for creating test cases and its testing capabilities can be extended by test libraries implemented either with Python or Java. Users can also create new keywords from existing ones using the same simple syntax that is used for creating test cases.