
Selenium has always been the first choicest tool for automation developers to develop the web automation framework. Selenium “Locator” is just a fancy word that is used to instruct the browser driver a path to find the right element.
Selenium locators are said to be one of the most powerful commands that act as building blocks of automation scripts. With the help of selenium locators, we can locate the application GUI elements to perform the desirable operations. These are one of the most sensitive parameters of Selenium where a little mistake in creating a selenium locator can fail the automation script, hence, the entire automation suite is dependent on selenium locators.
To interact with multiple web elements, we have multiple types of locators in Selenium WebDriver. Below is a list of the selenium locators available:
- ID
- Name
- Class Name
- XPath
- CSS Selector
- Linktext
- Partial Linktest
- Tag Name
- DOM Locator
Further, Selenium defines two below methods for identifying web elements:
- findElement : This method is used to uniquely identify a web element on a web page.
- findElements : This method is used to identify a list of web elements on a web page.
Now that we are clear with the introduction of selenium locators, it is important to know where exactly we can get or create Selenium locators to use in the automation scripts.
Quick Steps To Find Web Elements In Browser DOM
- Open up a web application and press F12 or right click and select ‘Inspect’ to open the browser DOM (Document Object Model)
- The default opened section would be named as ‘Element’ which is exactly what we need to locate elements. If the ‘Element’ section is not opened, click on the same to open it.
- Press CTRL + Shift + C to inspect an element and hover on the exact element for which the locator is required. Click on the GUI element to get the path of the same in DOM.
- To create your own locator, you can press CTRL + F which will open up the input text field from where we can create and validate our own locator.
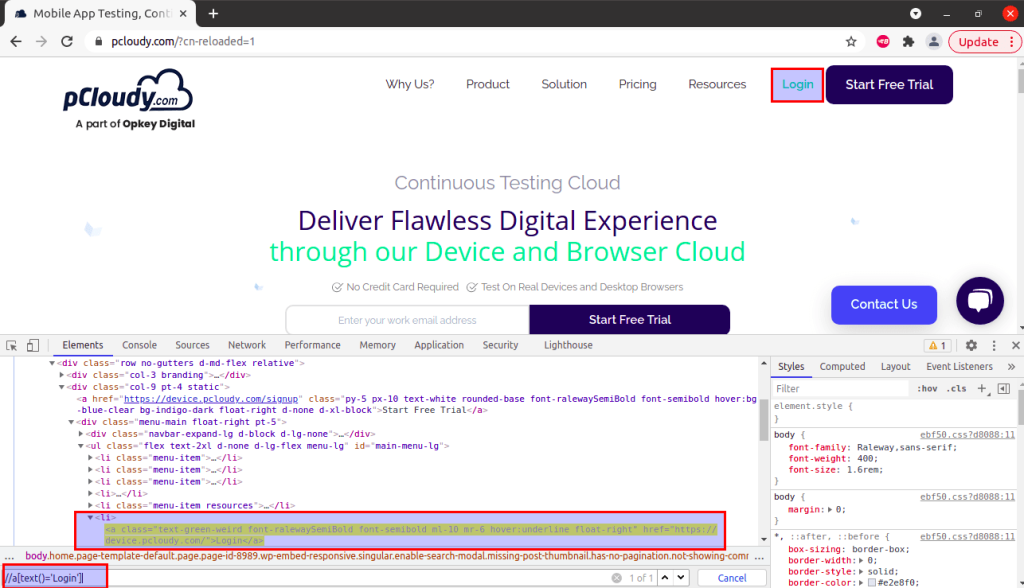
Locating ‘Login’ Button By Creating Own Locator – XPath
Types Of Locators In Selenium
The below steps will be helpful in briefing all types of locators in Selenium WebDriver.
1. ID Locator
This is one of the most common and easy ways of locating elements as the ID of an element is always unique in the DOM. According to W3C standards, ID’s of elements should always be unique which makes this locator fastest and safest to use.
However, it is a developer’s call whether they want to use the ID attribute or not as browsers can bypass this standard rule of W3C. So, we can still face a scenario where there is no ID of an element present in the DOM, in such case, we might need to use a different locating strategy to locate the DOM element uniquely. Example of ID locator:
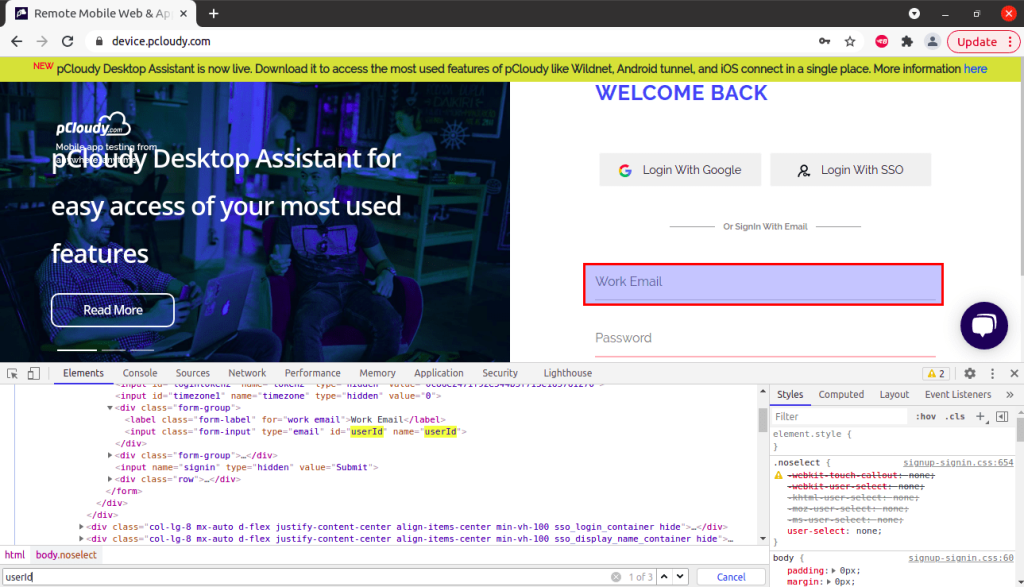
Syntax of locating ‘Work Email’ input field with ID locator is :
driver.findElement(By.id("userId"));
In case there are no element matches with id, NoSuchElementException will be raised.
2. Name Locator
A developer can define an element by its name which can further be used as a name locator by Selenium to locate an element. The name might not be unique, a web page can have multiple elements having the same name. In such a case, the browser driver selects the first locator in the DOM having that particular name.
Considering the same above web page screenshot of DOM, the syntax of locating ‘Work Email’ input field with Name locator is :
driver.findElement(By.name("userId"));3. Class Name Locator
The class name locator is helpful in locating elements that have class attributes defined in the DOM. The class name might not be unique, a web page can have multiple elements having the same class name. In such a case, the browser driver selects the first locator in the DOM having that particular class name.
Considering an example where there are same class names for two different elements:
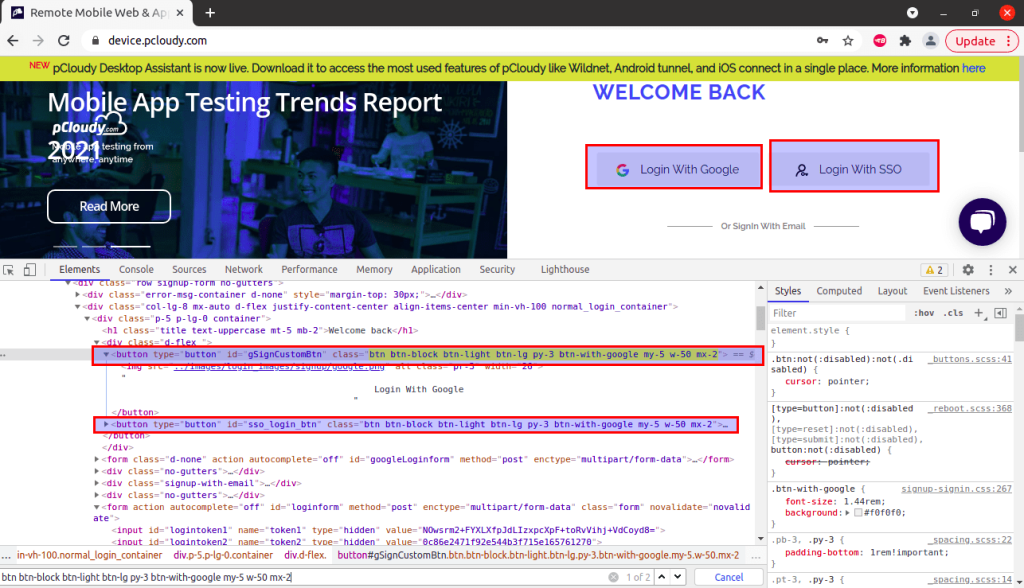
On a single web page, there are two buttons:
1) Login With Google
2) Login With SSO
As per the DOM structure, the class name of both buttons are same, in such case, the browser driver will locate the first button i.e. ‘Login With Google’ as it is placed first in the DOM compared to the second button.
Syntax to locate ‘Login With Google’ button via class name locator is:
driver.findElement(By.className("btn btn-block btn-light btn-lg py-3 btn-with-google my-5 w-50 mx-2"));4. Xpath Locator
XPath is a widely used locator that is created in a form of XML expression. XPath is mostly used to locate dynamic elements. If one used to fail to fetch a locator with id, name, or class name, then also one can easily locate an element with XPath.
The general syntax of XPath is : //Tagname[@Attibutename = ‘value’]
The above syntax defines four components:
- Double forward slash(//) – Represents the current node
- Tagname – Defines the tagname of a desired element
- Attributename – Defines attribute of a particular tag
- Value – Represents the value of a defined attribute
Types of XPath:
- Absolute XPath: This type of XPath provides the XML expression from root node to the desired element node. But there is a disadvantage: if there is a change of any node/tag between this expression, the whole XPath will fail to find an element. Absolute XPath starts with a forward slash(/).
Example: /html/body/div[1]/header/div/div[1]/div[3]/div/form/div[3]/div[1]/input
- Relative XPath: It provides the path starting from the middle of the HTML DOM structure and doesn’t start from a root node. It begins with a double forward slash.
Example: //*[@id=”twotabsearchtextbox”]
There are multiple ways through which xpath can be defined:
- Standard XPath
- Using Contains
- Using XPath with AND & OR
- Using starts-with
- Using text in XPath
Example of standard path :
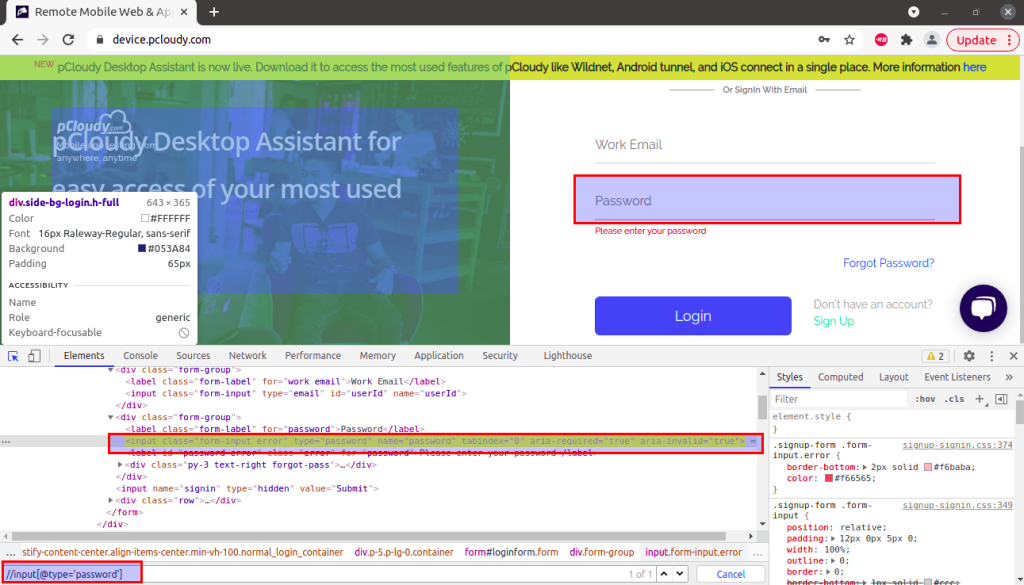
The XPath used to locate an element i.e. Password field is:
driver.findElement(By.xpath("//input[@type='password']"));5. CSS Selector Locator
Cascading style sheets are basically used to design web pages and has eventually become a Selenium locator to locate web elements. CSS is said to be more reliable than XPath and is faster than XPath.
The syntax used for identifying a web element with CSS locator is : (HTML Page)[Attribute=Value]
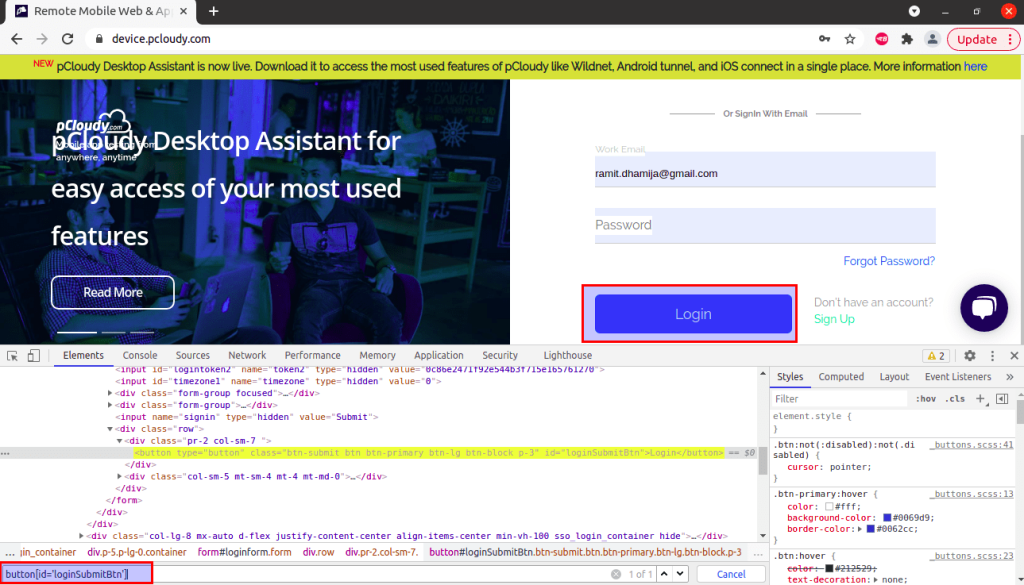
To locate ‘Login’ button via CSS locator, the code can be:
driver.findElement(By.cssSelector("button[id='loginSubmitBtn']"));6. Linktext Locator
Elements can be located via hyperlink text. Link text can only be used as an anchor tag as they are always prefixed with anchor tag. In a case where there are multiple links of the same text, the first link in the DOM will be selected by browser driver.
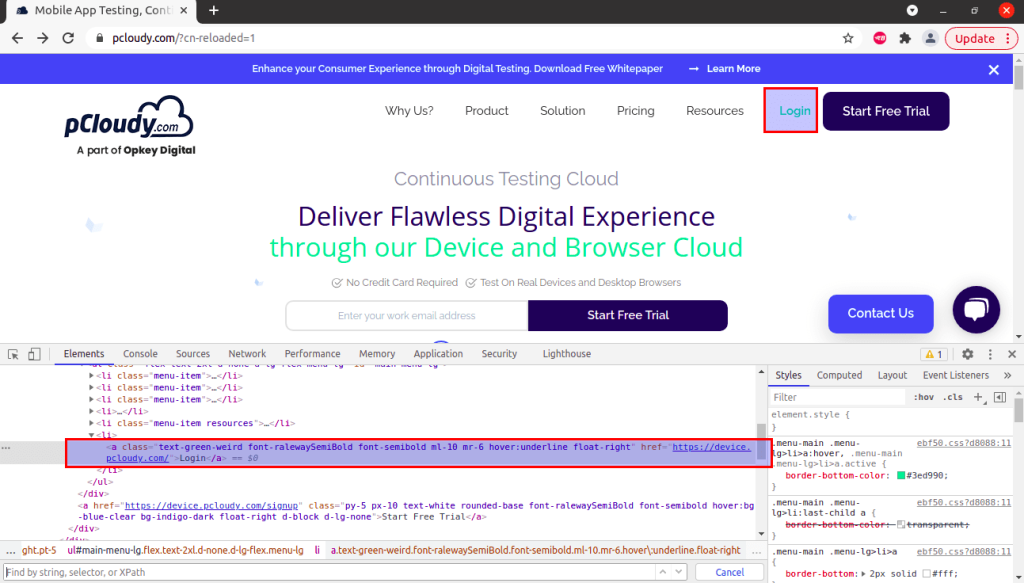
In the above DOM structure, we have an anchor tag having ‘href’ attribute containing the hyperlink of Login menu button. The linktext locator would be :
driver.findElement(By.linkText("Login"));7. Partial Linktext
Locating elements with Partial Linktext is probably similar to Link Text locator. Partial LinkText locator is mostly preferred when we have long link text and we prefer to use only the partial text over the entire link text to perform further operations. Sometimes, the intent of using partial linktext is to get all the elements of the web page having a common partial link text.
Considering the same above screenshot as attached in the example of LinkText locator, we can access the ‘Login’ button via Partial LinkText locator as well i.e. ‘Log’.
The syntax for locating element with partial link text is:
driver.findElement(By.partialLinkText("Log"));8. Tag Name Locator
As the name suggests, the Tag Name locator in Selenium uses tag names to identify elements on web pages. The tag name is basically the HTML tag such as input, div, button, anchor, span etc.
The tagName locator is usually used to fetch all the elements of the web page that contains a specified tag. For example, to get all the elements having anchor tag, the below syntax can be used:
driver.findElement(By.tagName("a"));Best Strategies To Locate Elements With Selenium Locators
Now that we are aware of some of the locators available in Selenium. It is important to know which locator is best to use for their respective testing scenarios. Similarly, it is equally important to know how to create locators that could be endlessly reliable for the entire automation suite. There are few strategic points listed below that should be taken care when locating an element:
- While creating XPath or CSS locator, do not copy the locator directly from browser dev tools: The XPath or CSS locator copied directly from dev tools might look tempting and easier to use, but this is very bad practise that must be avoided by automation developers. The XPath or CSS copied from dev tools are mostly complicated and have the longest path to the desired node which can cause slowness in execution of scripts and is not safe for long term as change of any element in the locator path can break the entire locator. Hence, creating your own locators have always been a great practise.
- Avoid using dynamic element values in your locators: There are multiple scenarios where we can see dynamic values of an element in the DOM. Whenever the web page loads, the element value gets changed. This is very common in case of ID locator where the web page can inject auto generated ID to a specific element everytime. Such cases can be handled by using the static prefix or postfix of the dynamic values. Or in case, you are aware of the logic of generating the exact dynamic value everytime that specific element needs to be located, you can write code based on the same logic.
- Do not locate elements based on indexing: The count of elements on a web page can increase or decrease based on the product requirement especially when the product is in initial development state. Hence, using index in XPath or any other locator is not recommendable as the value of element index can vary. Indexing is probably seen in the case of fetching elements from tables, menu headers or from lists and such UI elements can be handled by various other techniques as well like creating an array list and storing all the elements in array list and further iterating to get a particular element.
- Always prefer to choose a locator according to the fastest locating hierarchy: Since we have multiple locators provided by Selenium and all locators have their own way of execution, hence, the speed of locating elements of each locator definitely varies. Below is the list of locators from fast to slow speed:
- ID
- NAME
- CSS
- XPATH
How To Avoid Creating Duplicate Locators and Maintain The Locators In The Best Way?
An organisation that holds a huge technical product usually has a huge automation suite developed by a number of automation developers. Such a huge automation suite can land up to duplicacy in locators and find difficulty in maintaining locators.
Think of a scenario where the first automation developer is creating a script of ‘adding items in cart’ and the second automation developer is creating a script of ‘payment gateway’. The common web pages that both automation developers would face would be login page, product categorical page etc. In such a case, there is a possibility that both the automation developers can create their own locators of common pages which raises a problem of duplicacy.
The locators may change overtime, which may lead to changing the same failing locators everywhere in the suite. Hence, it is important to figure out a way to avoid creating duplicate locators and maintain the locators in a single repository. The solution that we need here is named as “Page Object Model”.
Page object Model is a design pattern and is not a framework. This design pattern provides a way to create an object repository to store references of web UI elements in a single place to develop web automation framework.
In the Page Object Model, we actually work on Pages and the “Page” here refers to class/repository which would be storing web page corresponding locators and methods to perform operations on those web pages.
For a small test automation project, using Page Object Model doesn’t matter, however, when we are working on a test automation for a large growing hybrid automation project, it is highly recommended to use Page Object Model. For huge products, the test suite typically grows overtime, hence it would become difficult to maintain those test scripts if a certain design pattern is not followed.
Example: We have 25 scripts in our automation test suite for 25 different test cases and they do have common web elements interaction. Any change in these elements will force us to change the locators in all 20 scripts which would be obviously time consuming and difficult to maintain. Hence, while developing an automation suite, it is highly recommended to use Page Object Model or a similar design pattern where the application locators can be stored at one single place so that modification of such locators doesn’t consume much time when required.
Advantages of using Page Object Model
- Helps in easy maintenance of the automation test suite.
- Develops scripts in a more readable format.
- Makes scripts reusable.
- Efficient and reliable.
Disadvantages of using Page Object Model
- Initially it requires a high amount of effort and time to set up the model.
- Requires technical sounding testers with good programming practises.
Conclusion
Selenium Locators are a great way to accelerate our testing efforts by using the locators in our Automation Test scripts. While the initial effort may sound like a daunting task, the efforts pay off as we reuse the automation script multiple times. Knowing how and when to use the locators in a script is key to writing an effective test automation script. We hope this blog helps you get a basic understanding of using locators and their benefits. Also, feel free to download a free whitepaper on setting up your Selenium grid with Docker.




